Wstęp
Zarządzanie infrastrukturą za pomocą kodu to trend, który zdobywa coraz większą popularność i powoli staje się standardem. Klienci rzadziej niż kiedyś wyrażają chęć korzystania z tradycyjnego, manualnego podejścia, a coraz częściej stawiają na automatyzację przy pomocy IaC. Gdy rozmawiamy o tym, jak zarządzać infrastrukturą przy pomocy kodu, jedno narzędzie pojawia się najczęściej w rozmowach – Terraform. To rozwiązania spod szyldu HashiCorp zyskuje uznanie dzięki swojej czytelnej składni, dojrzałości i elastyczności. Jeśli dopiero wprowadzasz swoją organizację do świata chmury publicznej, masz o tyle łatwiej, że od samego początku możesz zaimplementować podejście IaC. Ale co w przypadku, gdy twoja organizacja już korzysta z chmury publicznej i posiada zasoby utworzone manualnie, które nie mają odzwierciedlenia w kodzie? Tutaj pojawia się problem. Architektura Terraform do tej pory miała spore trudności z tymi zasobami. Importowanie ich do kodu stanowiło tylko część zadania, ponieważ kolejnym krokiem było wprowadzenie ich do stanu Terraform. Nie było to łatwe, ponieważ każdy zasób musiał być importowany oddzielnie. Jednak wprowadzenie funkcjonalności „config-driven import” w najnowszej wersji 1.5 Terraform’a powinno rozwiązać ten problem. Ale czy na pewno?
Config-driven Import
Przyjrzyjmy się teorii. HashiCorp wprowadził do swojego rozwiązania nowy rodzaj bloków, znanych jako bloki typu „import”. Dzięki nim możemy zaplanować importowanie zestawu zasobów, podobnie jak planujemy masowe wdrożenia za pomocą Terraform. Struktura bloków typu import jest niezwykle prosta, jak możemy zobaczyć poniżej:
import {
id = “i-abcd1234”
to = aws_instance.example
}
Jak widzicie, struktura jest bardzo prosta, otwieramy blok import, podajemy id naszego zasobu oraz musimy zadeklarować typ, oraz nazwę obiektu, do którego zasób zostanie zaimportowany.
Import
Zacznijmy od prostego środowiska, w którym mamy NSG stworzone za pomocą Terraform, oraz parę zasobów, które zostały utworzone ręcznie. Nasze NSG powstaje z poniższego kodu.
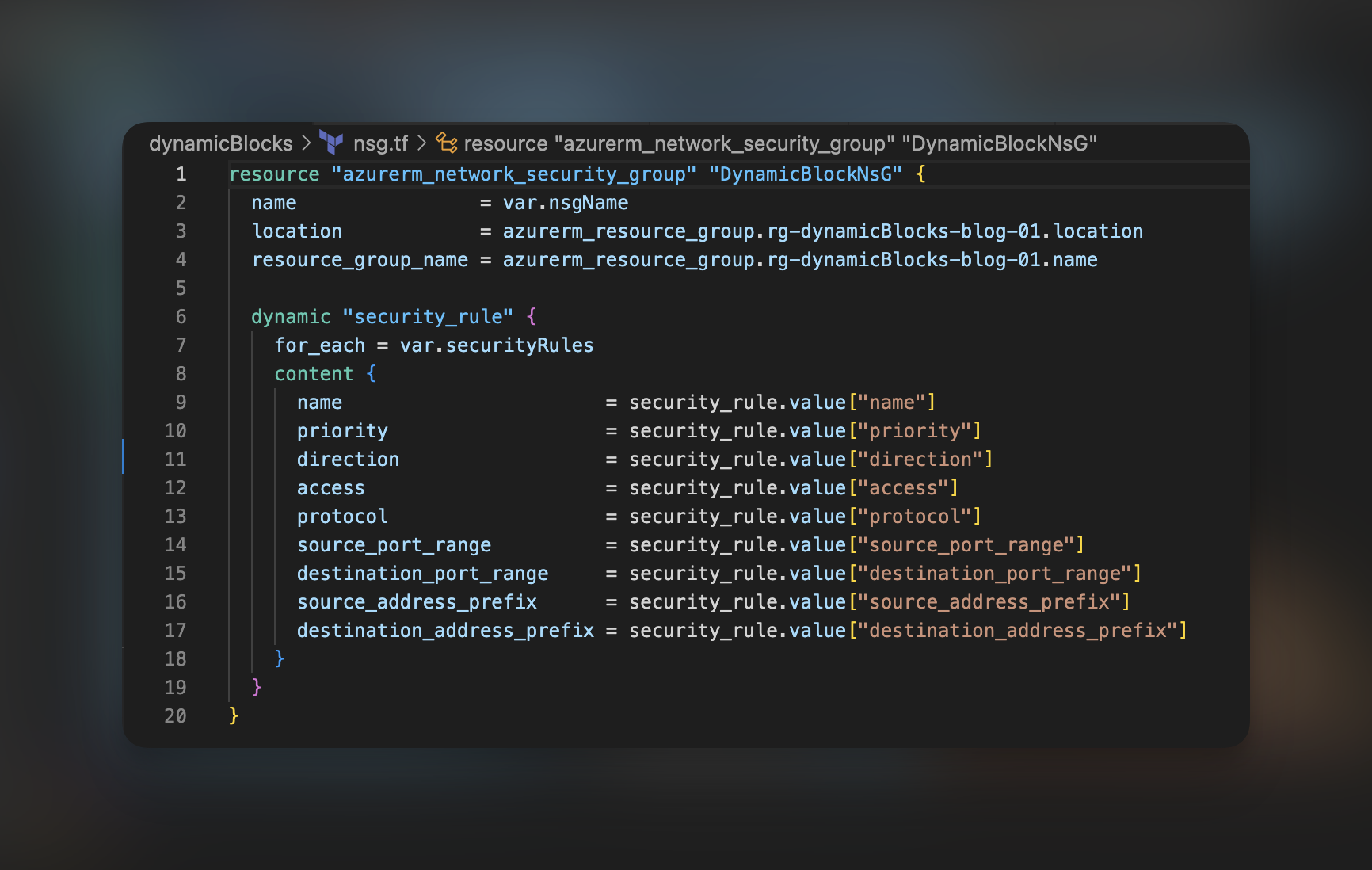
Dodatkowo stworzyliśmy manualnie parę zasobów: dwie wirtualne sieci, publiczne ip, oraz kartę sieciową.
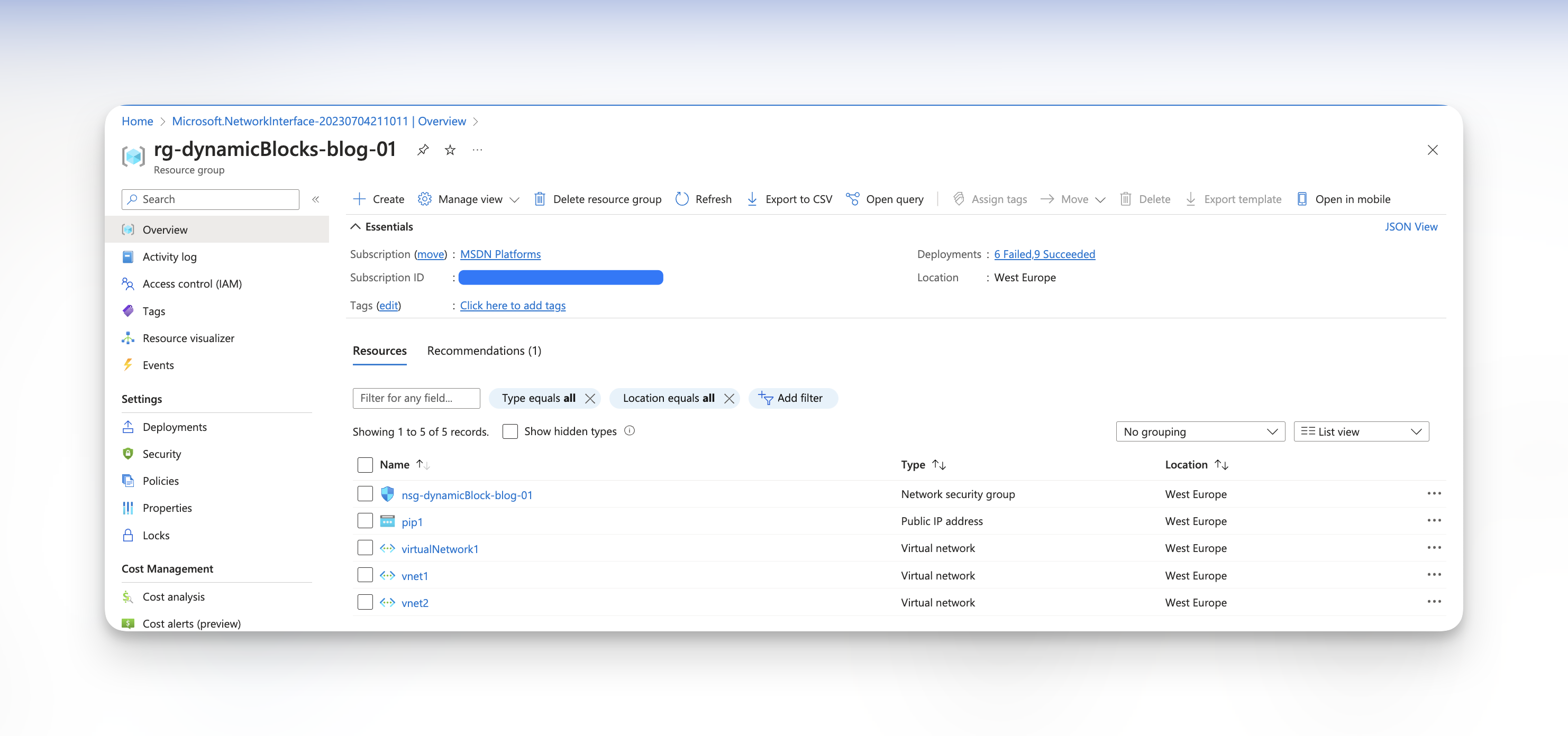
Spróbujmy teraz zaimportować te zasoby do naszego kodu oraz state’a Terraform. Aby to zrobić, musimy wykorzystać bloki typu Import podając w nich wspomniane już id zasobów oraz nazwy obiektów, które zostaną stworzone przez Terraform.
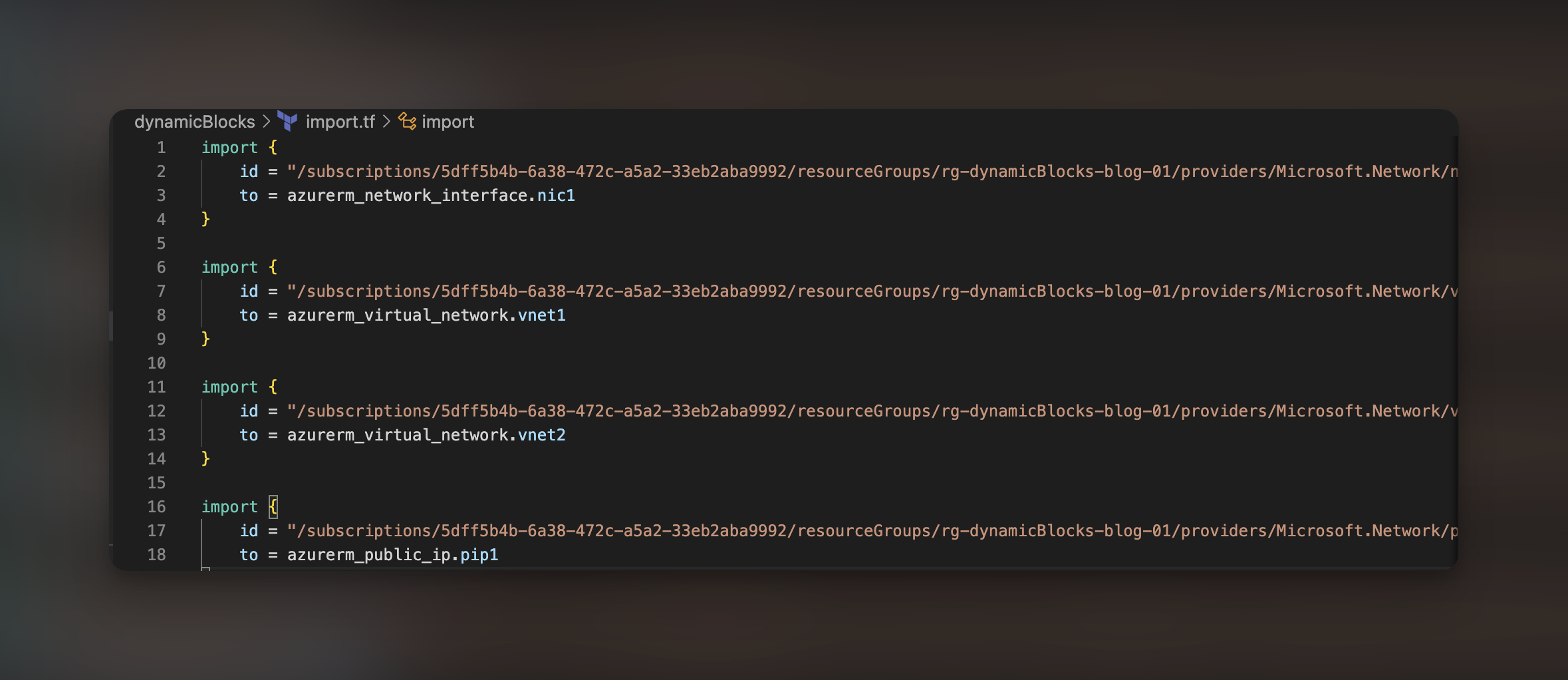
Posiadając już kod potrzebny do masowego importu zasobów, możemy wykonać operacje planu. Aby plan wygenerował nam dodatkowo pliki konfiguracyjne do zaimportowanych zasobów możemy dodać flagę – „-generate-config-out=generated_resources.tf . Gdzie generated_resources.tf będzie nazwą pliku, w którym znajdzie się wygenerowany kod. Zanim wykonamy tę komendę zerknijmy również na status naszego terraform state. Możemy zauważyć, że obecnie znajduję się w nim NSG oraz resource group.
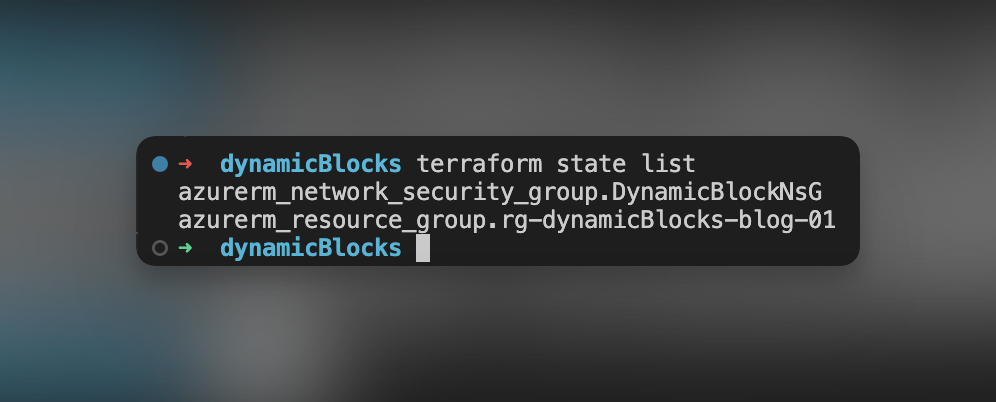
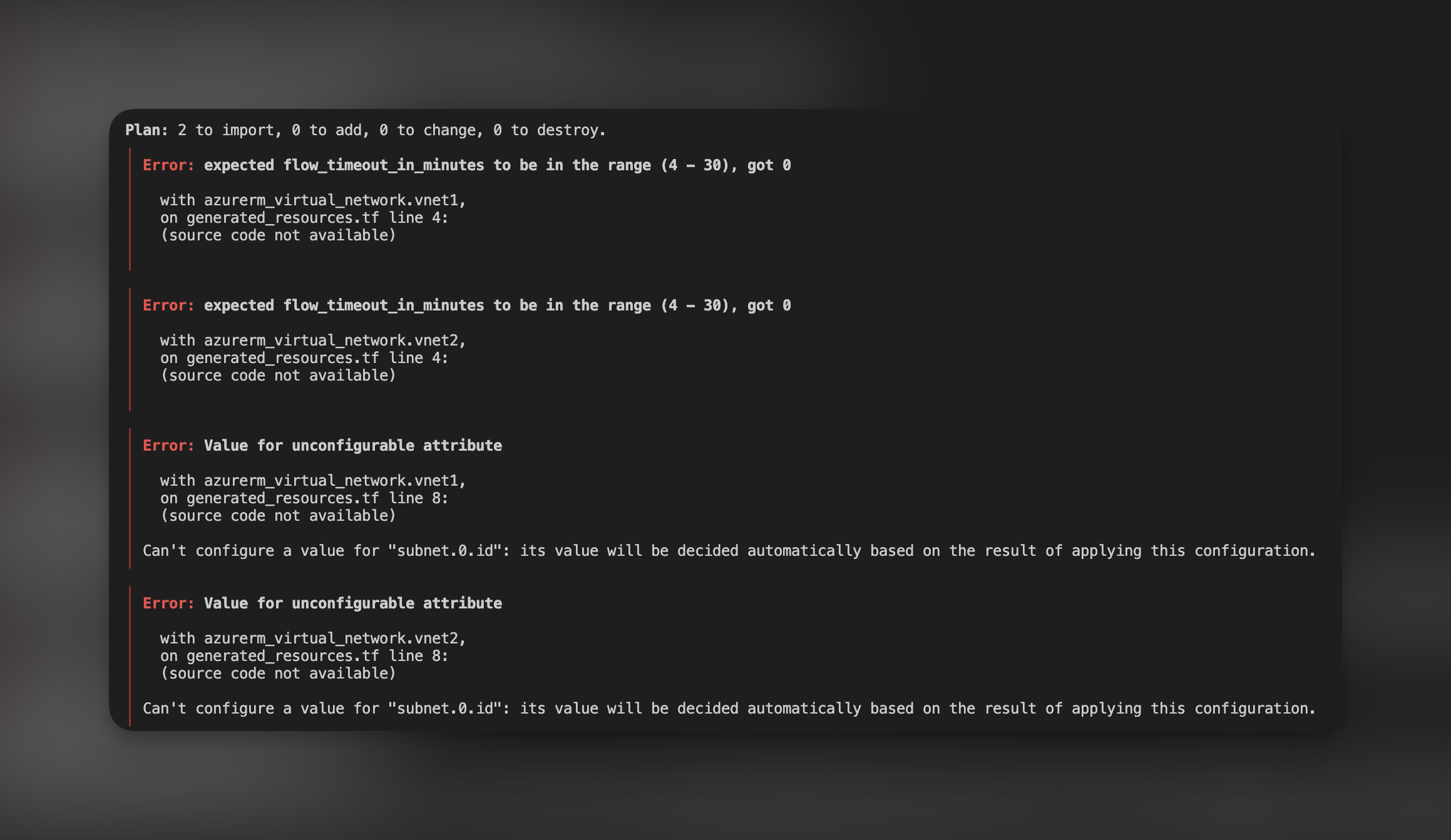
Wykonanie komendy Terraform plan odnosi połowiczny sukces. Otrzymujemy informację, że część zasobów została zaimportowana. Jednakże dla grupy zasobów Terraform napotkał na problem.
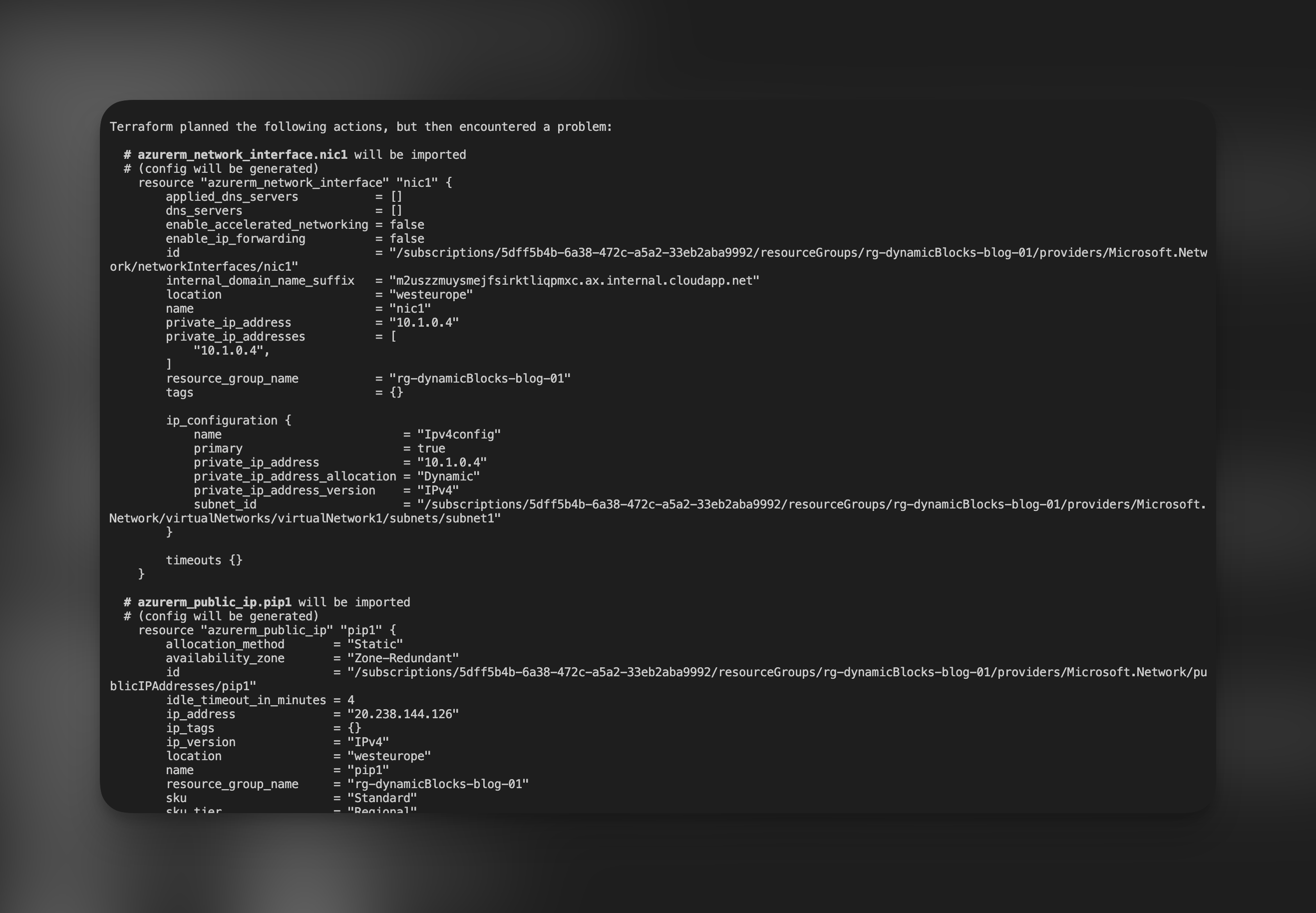
Spójrzmy jednak na wygenerowany kod do zasobów, które zostały dostrzeżone przez Terraform w chmurze. Najpierw spójrzmy na kod zasobu, który działa, czyli konfigurację publicznego IP. 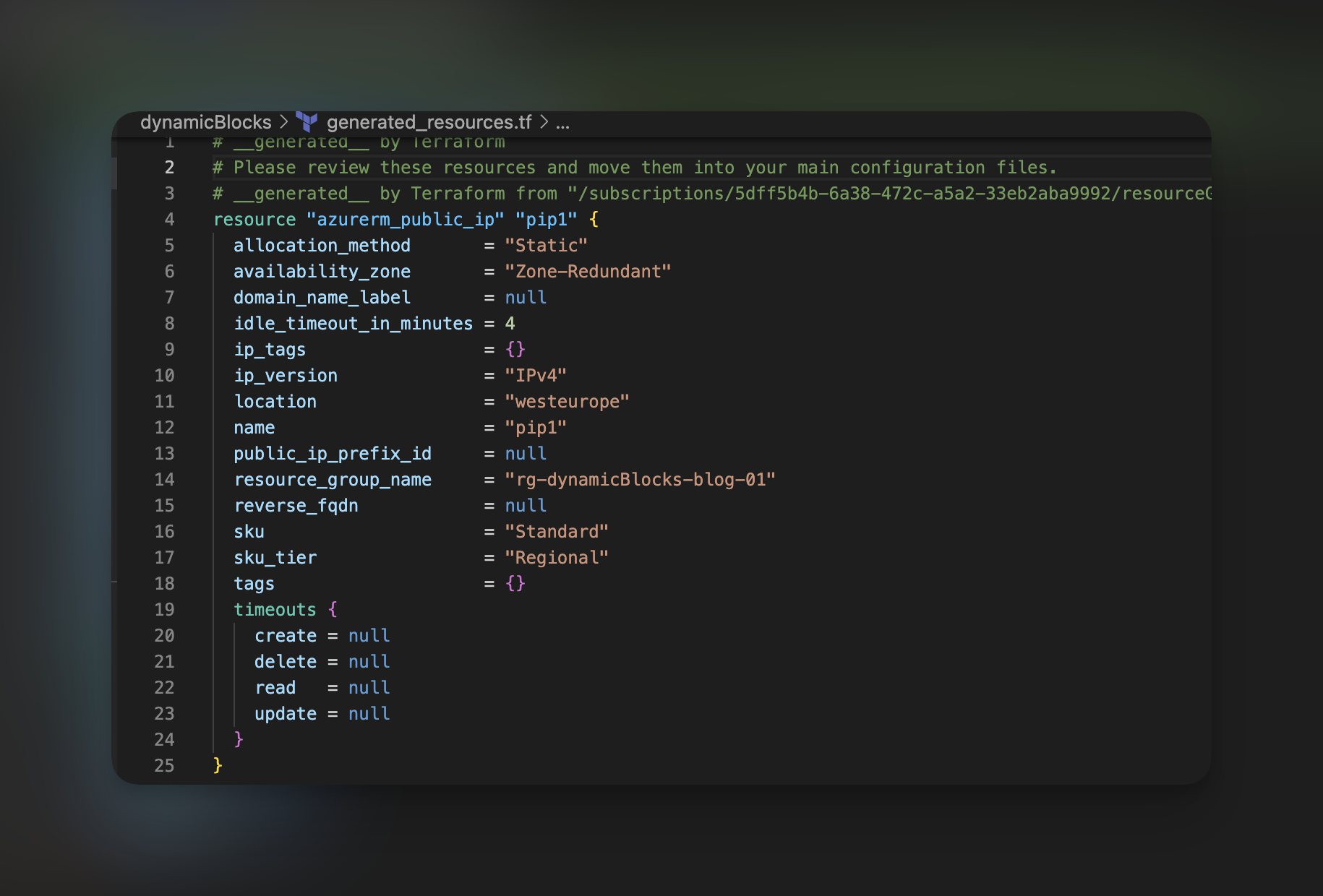
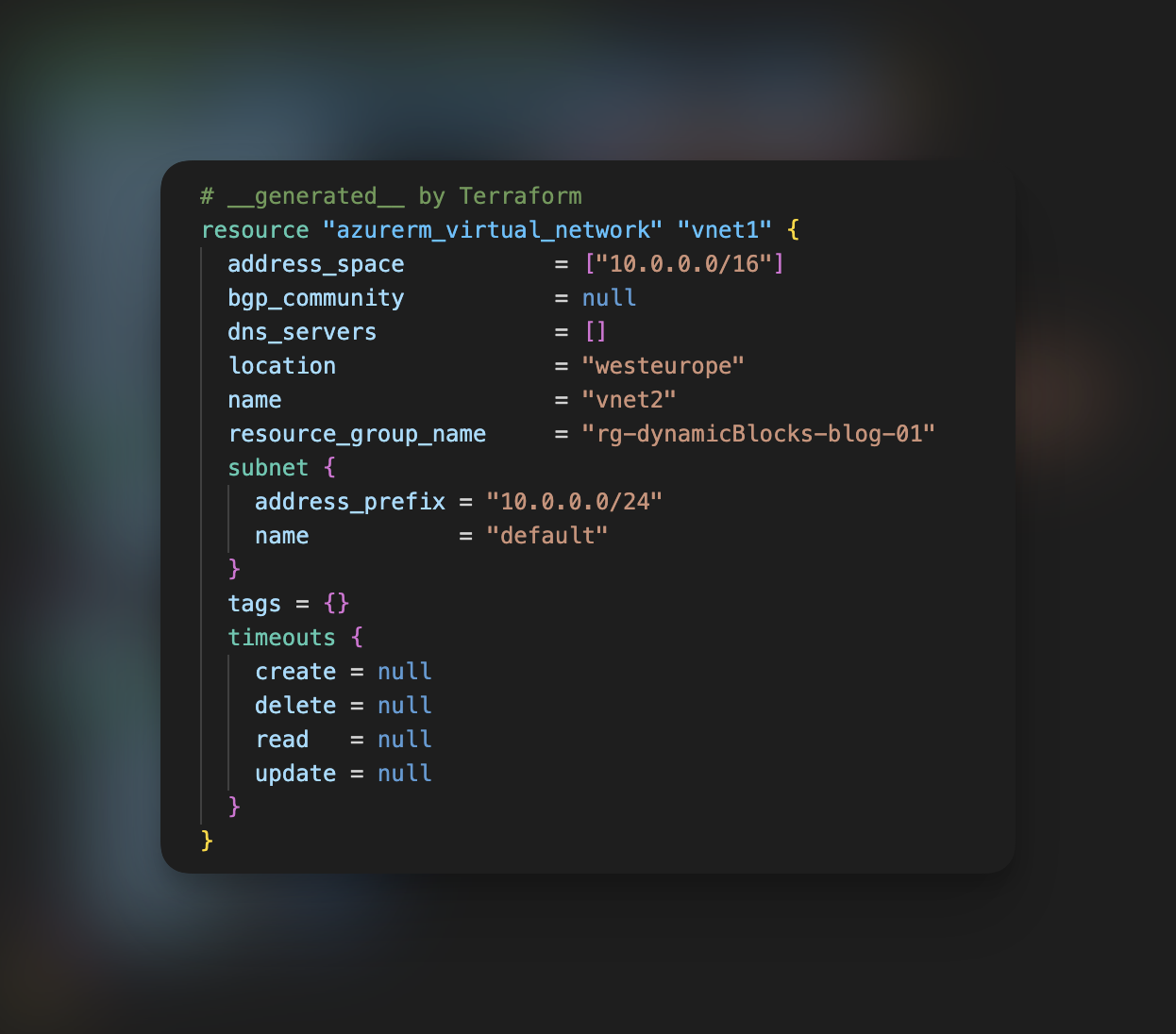
Gdy spojrzymy na to, co pierwsze rzuca się nam w oczy, od razu zauważymy kilka ustawień, które są zbędne dla naszego konkretnego zasobu. Timeouty, które się pojawiają, oraz kilka pustych parametrów, takich jak domain_name_label, są tylko przykładem tego nadmiaru. Ale to nie wszystko, co sprawia, że ten import ma swoje ograniczenia. Brakuje w nim parametryzacji i wykorzystania funkcji, co oznacza, że nie będziemy w stanie automatycznie generować wartości dla parametrów zasobu. Teraz przechodzimy do zasobu, który sprawiał nam problemy – wirtualnej sieci.
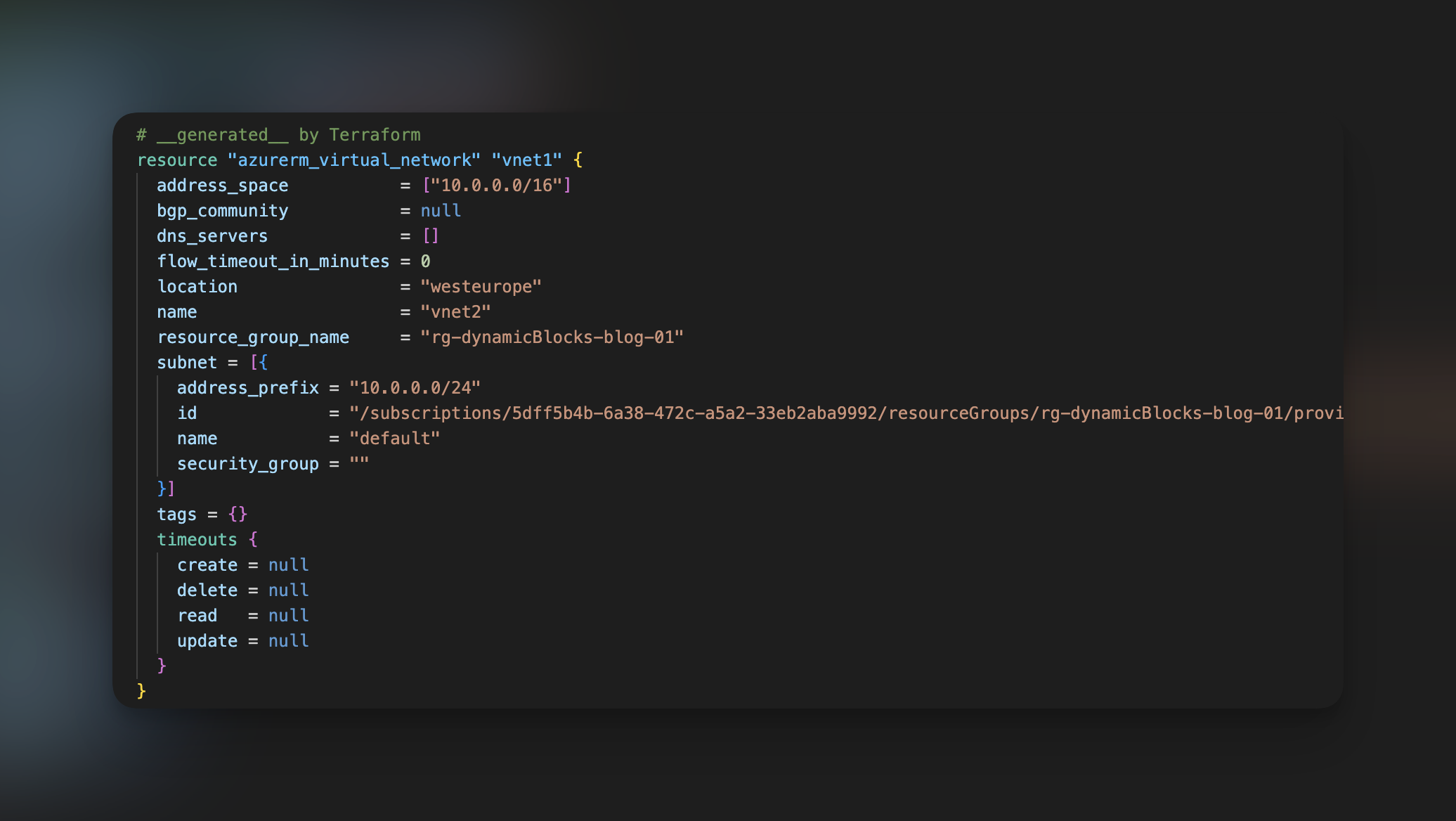
Nie dość, że widzimy tu te same braki co w przypadku poprzedniego zasobu, to jeszcze wiemy, że ten kod wygenerował nam dwa problemy. Jeden odnosi się do parametru „flow_timeout_in_minutes”, który musi zawierać się w zakresie od 4-30m, oraz drugi, który mówi, że definicja subnetu jest niepoprawna, ponieważ zawiera jego ID. W takim przypadku należy zrozumieć problem oraz sprawdzić dokumentację w celu sprawdzenia poprawnej struktury definicji konkretnych zasobów. W naszym przypadku wystarczyło usunąć parametr „flow_timeout_in_minutes” oraz przerobić definicję subnetów. Po modyfikacji nasz kod prezentuję się tak:
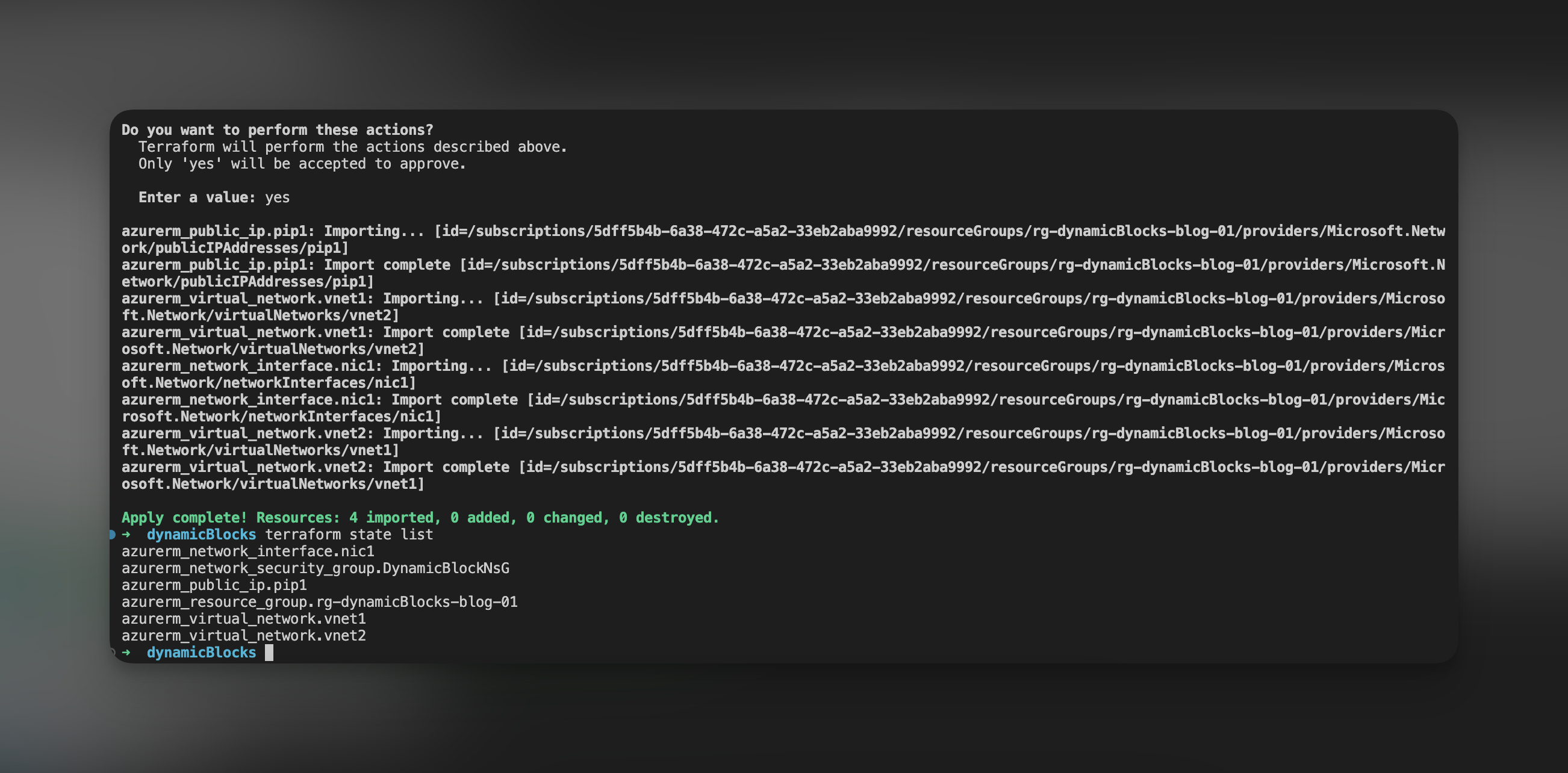
Po edycji błędnie zdefiniowanych zasobów ponownie uruchamiany terraform plan, a następnie apply. Po poprawnie wykonanym apply otrzymamy informację na temat ilości zaimportowanych zasobów oraz nasz terraform state będzie zawierał zaimportowane zasoby.
Podsumowanie
Terraform w wersji 1.5 wkracza na nowy poziom, wprowadzając funkcjonalności, które dotychczas były dostępne jedynie za pośrednictwem rozwiązań społecznościowych. To ważny krok naprzód dla HashiCorp, który ułatwi rozmowy z klientami poszukującymi takich narzędzi. Jednakże, choć nowe możliwości są pozytywnym rozwojem, nie można uznać ich za rozwiązanie idealne. W rzeczywistości są one dość proste w działaniu. Dlatego dla dojrzałych organizacji nie stanowią one narzędzia „szybkiego sukcesu”, lecz raczej solidnego fundamentu, który będzie musiał zostać dostosowany do specyfiki danej organizacji.